Gescande PDF’s
Scannen van pagina's uit oude studieboeken resulteert in documenten die niet toegankelijk zijn
Het voorbereiden van een cursus brengt heel wat werk met zich mee. Het kan gebeuren dat je soms een gescande kopie van een boek tussen je bestanden hebt zitten. Helaas zijn gescande teksten zeer slecht toegankelijk en zijn ze voor alle studenten lastig om te lezen en op te nemen.
Als je een gescande PDF tegenkomt, is het raadzaam om deze te vervangen door een goede digitale tekstversie van het document.
Gescande PDF’s krijgen een lage toegankelijkheidsscore.

Selecteer de indicator Toegankelijkheidsscore voor meer informatie en om een beschrijving toe te voegen.
Toelichting van probleem en informatiebronnen
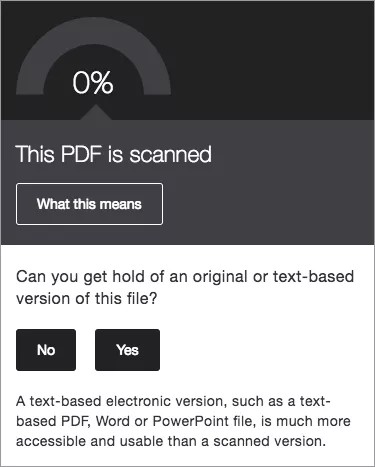
Het bestand is 0% toegankelijk omdat het voor alle studenten lastig is om het materiaal te lezen en op te nemen.
Selecteer Wat betekent dit voor een uitleg.
Een tekstversie uploaden
Heb je een tekstversie? Selecteer dan Ja en upload een versie met digitale tekst naar Ally om de score te verbeteren.
Een bibliotheekreferentie toevoegen
Het kan lastig zijn om een versie met digitale tekst te vinden. Overleg voor het begin van het semester met de bibliothecaris of administratie om er zeker van te zijn dat studenten die deze bestandsformaten nodig hebben niet achterop raken.
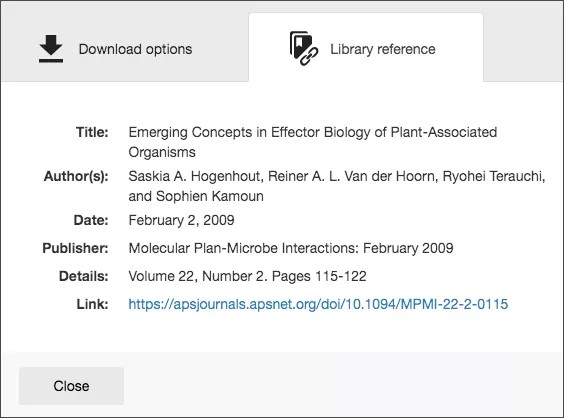
Je kunt ook een bibliotheekreferentie toevoegen aan Ally om je studenten te helpen.
- Selecteer Nee op de vraag of je aan de originele of een op tekst gebaseerde versie van het bestand kunt komen.
- Selecteer Ja op de vraag of het document in de bibliotheek kan worden gevonden.
- Voer in het feedbackformulier van Ally zo veel mogelijk gegevens in en selecteer vervolgens Verwijzing toevoegen.
Nadat je de bibliografische gegevens hebt toegevoegd, kunnen studenten de documentgegevens raadplegen door naar het bestand te gaan en Alternatieve formaten te selecteren in het menu naast de bestandsnaam. Selecteer Bibliotheekreferentie.
Alternatieve OCR-indeling
Als je in het feedbackvenster van Ally voor beide vragen Nee selecteert, voert Ally OCR (Optical Character Recognition) uit om te proberen de tekstelementen beter te herkennen. Helaas is dit geen definitieve oplossing en dus blijft de score hetzelfde. Het is nog steeds wenselijk om de gescande versie te vervangen als dat mogelijk is.